自从SDXL大模型发布以后,ComfyUI因为更符合Stable Diffusion的底层工作原理,在图片生成速度上相比WebUI有了质的飞跃。这让越来越多想要深入了解SD工作机制的创作者,开始把目光投向了ComfyUI。
那么ComfyUI究竟是什么?使用它有哪些实实在在的好处?又该如何快速上手呢?
这期视频,我将为你全面解析ComfyUI——从基础概念到实战应用,从安装配置到工作流搭建。学完之后,你不仅能快速掌握ComfyUI的核心功能模块,理解它与WebUI之间的对应关系,还能独立使用SDXL模型创作高质量作品。

ComfyUI是什么?
ComfyUI是一个基于节点流程的Stable Diffusion AI绘图工具。如果你之前接触过Houdini、Blender、Unreal Engine等节点式软件,那么上手ComfyUI会非常轻松。
它的核心理念是:将Stable Diffusion的生成流程拆解成独立模块,通过可视化的节点连接,实现更精准的工作流定制和完善的可复现性。
为什么选择ComfyUI?
1. 高度自定义的工作流
当你对ComfyUI的模块节点有足够了解后,可以轻松定制专属工作流。在进行复杂的长线项目时,你可以搭建特殊的自动化流程,让任务排队运行,不再需要坐在电脑前反复等待渲染完成,再手动执行下一步操作。
2. 轻量化设计,性能更优
ComfyUI的轻量化特性使其在使用SDXL模型时,拥有更低的显存要求和更快的加载速度。生成大尺寸图片时也不容易爆显存,这对配置有限的用户来说是巨大优势。
3. 专业性与易用性兼得
无论是自由度、专业性还是实际易用性,ComfyUI在使用SDXL模型上的优势都越来越明显,已经成为专业创作者的首选工具。
详细安装教程
下载安装包
首先,打开ComfyUI官方发布的GitHub地址,找到最新版本的安装包直接下载。为了方便大家,我已经整理好了官方安装包和推荐使用的工作流,全部放在了视频简介中,可以直接下载使用。
安装步骤(超级简单)
- 解压文件:下载完成后,将压缩包解压到一个空间充足的硬盘分区
- 直接使用:解压后即可使用,无需复杂配置
注意:官方安装包仅支持Windows系统
- 如果你使用的是英伟达显卡,双击运行
run_nvidia_gpu.bat - 如果不是英伟达显卡,则运行
run_cpu.bat(但速度会慢很多)
首次启动
运行后会自动跳转到ComfyUI的网页界面,或者你也可以手动复制控制台显示的链接到浏览器中打开。
模型配置指南
刚安装好的ComfyUI是没有任何模型的,我们需要手动配置各种模型文件。
模型存放位置
不同类型的模型需要放置到ComfyUI文件夹下的 models 目录中:
- 大模型放在
checkpoints文件夹 - LoRA模型放在
loras文件夹 - VAE文件放在
vae文件夹 - 以此类推
链接WebUI模型(节省硬盘空间)
如果你之前使用过WebUI,已经有一整套模型库,直接复制会浪费大量硬盘空间。ComfyUI的作者贴心地提供了模型路径链接功能:
操作步骤:
- 在ComfyUI根目录找到
extra_model_paths.yaml.example文件 - 将文件名的
.example后缀删除,改为extra_model_paths.yaml - 右键选择用记事本打开该文件
- 找到
base_path这一行,填入你的WebUI根目录完整路径 - 保存文件,重新启动ComfyUI
现在再打开ComfyUI,选择模型时就能看到所有WebUI中的模型了,完全不占用额外空间!
后续更新
如果想要更新ComfyUI版本,只需打开 update 文件夹,运行其中的更新脚本即可自动完成。
界面基础与工作流详解
默认文生图工作流解析
打开ComfyUI后,你会看到一个最基本的文生图工作流。让我们逐一了解每个模块的作用:
1. Load Checkpoint(加载模型)
这就是WebUI中选择大模型的地方。点击下拉菜单可以选择你想使用的主模型。
这个模块有三个输出节点:
- MODEL:连接到采样器
- CLIP:连接到提示词编码器
- VAE:连接到图像解码器
2. CLIP是什么?
CLIP是由OpenAI开发的神经网络模型,它能将自然语言和视觉信息进行联合训练,实现图像与文本之间的跨模态理解。在Stable Diffusion中,CLIP负责理解和编码你输入的提示词。
3. CLIP Text Encode(提示词编码)
这是写提示词的地方,分为正向提示词和负向提示词两个模块:
- 绿色模块:正向提示词(你想要的内容)
- 红色模块:负向提示词(你不想要的内容)
它们分别连接到KSampler模块的 positive 和 negative 节点。
4. KSampler(采样器)
这就是WebUI中的采样器设置,可以调整:
- 采样方法(Sampler)
- 调度器(Scheduler)
- CFG值
- 步数(Steps)
- 随机种子(Seed)
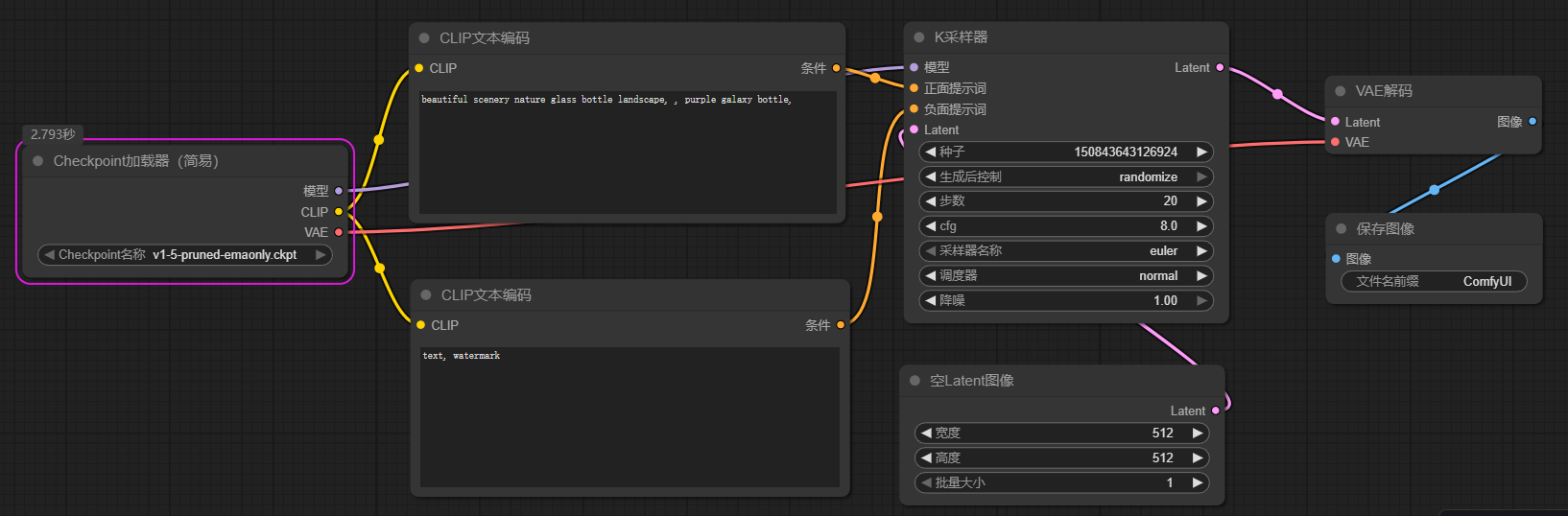
KSampler的输入节点包括:
- model:来自Load Checkpoint
- positive/negative:来自提示词编码器
- latent_image:来自Empty Latent Image
5. Empty Latent Image(空白潜空间图像)
用于设置生成图像的参数:
- 宽度(Width)
- 高度(Height)
- 批次数量(Batch Size)
6. VAE Decode(VAE解码器)
KSampler产生的是潜空间(Latent Space)的图像数据,需要经过VAE Decode解码,还原到像素空间,才是我们最终看到的图像。
连接要点:
- samples 节点:连接KSampler的输出
- vae 节点:连接Load Checkpoint的VAE输出
7. Save Image(保存图像)
用于展示和保存最终生成的图像。
基础操作流程
了解了这些模块,生成图片的流程就非常简单了:
- 在Load Checkpoint中选择模型
- 在提示词模块中写好正负向提示词
- 调整采样器参数和图像尺寸
- 点击右侧的 Queue Prompt 按钮开始生成
生成完成后:
- 点击 Save 保存当前工作流
- 点击 Load 可以导入其他工作流
- 也可以直接拖拽工作流图片到界面中自动加载
SDXL工作流实战
现在让我们导入官方的SDXL标准工作流,实际操作一遍完整流程。
SDXL工作流结构
我已经为每个模块添加了中文备注,方便大家理解。SDXL工作流的核心特点是使用了 Base模型 + Refiner模型 的两阶段生成方式。
详细设置步骤
第一步:加载模型
在最左侧有两个Load Checkpoint模块:
- 上方模块:选择SDXL Base模型
- 下方模块:选择SDXL Refiner模型
第二步:编写提示词
在Text Prompts模块中:
- 绿色框:填写正向提示词(描述你想要的画面)
- 红色框:填写负向提示词(描述你不想要的元素)
第三步:设置图像尺寸
在Empty Latent Image模块中设置:
- 宽度和高度:SDXL模型建议使用1024×1024或更高分辨率,能获得更好的效果
- 生成数量:Batch Size
第四步:配置采样器
这个工作流有两个KSampler,分别对应Base模型和Refiner模型,可以独立调整参数。
重点关注Step Control模块:
- steps:总步数(例如25步)
- end_at_step:Base模型结束的步数(例如20步)
这意味着:前20步使用Base模型生成,后5步使用Refiner模型精修。
推荐配置:
- Refiner模型的步数通常是Base模型的20%左右
- 例如总共25步,Base用20步,Refiner用5步
第五步:生成图像
所有参数设置完成后,点击 Queue Prompt 开始生成。整个流程和WebUI的逻辑差别不大,但更加直观和可控。
SDXL参数优化建议
如果你对SDXL模型还不够了解,建议观看我之前的SDXL详解视频,里面详细讲解了:
- SDXL模型的核心优势
- 推荐使用的参数配置
- 常见问题解决方案
- 最佳实践技巧
更多工作流资源
想要探索更多高级工作流吗?
官方示例库
- 打开ComfyUI的GitHub主页
- 找到 ComfyUI Examples 链接进入
- 这里有大量官方制作的常用工作流,包括:
- 图生图工作流
- ControlNet工作流
- LoRA使用工作流
- 局部重绘工作流
- 高清修复工作流
- 批量处理工作流
导入工作流的方法
超级简单:
- 在GitHub页面上右键保存工作流图片
- 直接拖拽图片到ComfyUI界面
- 工作流会自动识别并加载
你也可以参考官方的节点连接方式,对现有工作流进行个性化调整。
重要提醒:调整好工作流后,一定要记得点击 Save 保存,方便日后快速导入使用。
总结
ComfyUI是一个功能强大、灵活高效的Stable Diffusion系统。它支持各种先进功能和模型,为AI艺术创作提供了极大的便利性和专业性,使艺术家能够更加轻松地创造出令人惊艳的图像和作品。
相比传统的WebUI:
- 性能更优:显存占用更低,生成速度更快
- 更加灵活:工作流可视化,自定义程度高
- 更专业:适合批量处理和复杂项目
- 可复现性强:工作流可以保存和分享